É|µ¿—–æø‘∫≈c IDEA —–æø‘∫¬ì(li®¢n) ÷¥Ú‘Ï∂ÀµΩ∂À’Z(y®≥)“Ù¥Ûƒ£–ÕUniTTS£¨÷˙¡¶∂ÀÇ»(c®®)»ÀôC(j®©)Ωªª•∞l(f®°)’π

°°°°‘⁄Æî(d®°ng)ΩÒîµ(sh®¥)◊÷ªØïr(sh®™)¥˙£¨»ÀôC(j®©)Ωªª•“—≥…ûÈ»ÀÇÉ…˙ªÓ÷–≤ªø…ªÚ»±µƒ“ª≤ø∑÷°£èƒ÷«ƒÐ ÷ôC(j®©)…œµƒ’Z(y®≥)“Ù÷˙ ÷µΩ÷«ƒÐº“攑O(sh®®)ljµƒ’Z(y®≥)“Ùøÿ÷∆£¨»ÀôC(j®©)’Z(y®≥)“ÙΩªª•ºº–g(sh®¥)’˝“‘Û@»ÀµƒÀŸ∂»∏ƒ◊É÷¯Œ“Çɵƒ…˙ªÓ∑Ω Ω°£»ª∂¯£¨“™åç(sh®™)¨F(xi®§n)’Ê’˝◊‘»ª°¢¡˜ï≥«“∏ª”–«È∏–µƒ»ÀôC(j®©)’Z(y®≥)“ÙΩªª•£¨“¿»ª√Ê≈R÷T∂ýÃÙë(zh®§n)°£Ç˜Ωy(t®Øng)’Z(y®≥)“ÙΩªª•œµΩy(t®Øng)‘⁄Ãé¿Ì“ÙÓl–≈œ¢ïr(sh®™)£¨Îy“‘≥‰∑÷≤∂◊Ω∫Õ¿˚”√“ÙÓl÷–µƒ∏±’Z(y®≥)—‘Ãÿ’˜£¨±»»Á“Ù…´°¢Ì笅∫Õ«È∏–µ»£¨þ@ πµ√”…ôC(j®©)∆˜…˙≥…µƒ’Z(y®≥)“Ù‘⁄◊‘»ª∂»∫Õ«È∏–±Ìþ_(d®¢)∑Ω√ʥʑ⁄≤ª◊„°£¥ÀÕ‚£¨ÎS÷¯»Àπ§÷«ƒÐºº–g(sh®¥)µƒ≤ªîý∞l(f®°)’𣨻ÀÇÉå¶(du®¨)’Z(y®≥)“ÙΩªª•œµΩy(t®Øng)µƒ“™«Û“≤‘ΩÅÌ(l®¢i)‘Ω∏þ£¨≤ªÉHœ£Õ˚À¸ƒÐú (zh®≥n)¥_¿ÌΩ‚≤¢àÃ(zh®™)––÷∏¡Ó£¨∏¸∆⁄Õ˚À¸ƒÐœÒ»ÀÓê(l®®i)“ªò”£¨Õ®þ^(gu®∞)’Z(y®≥)“Ùǘþf«È∏–∫ÕÇÄ(g®®)–‘°£
°°°°ûÈ¡ÀÕª∆∆þ@–©œÞ÷∆£¨åç(sh®™)¨F(xi®§n)∏¸º”◊‘»ª°¢÷«ƒÐµƒ∂ÀÇ»(c®®)»ÀôC(j®©)’Z(y®≥)“ÙΩªª•ÛwÚû(y®§n)£¨É|µ¿—–æø‘∫≈cªõ∏€∞ƒ¥Ûû≥Ö^(q®±)îµ(sh®¥)◊÷Ωõ(j®©ng)ù˙(j®¨)—–æø£®IDEA—–æø‘∫£©¬ì(li®¢n)∫œåç(sh®™)Úû(y®§n) “£®COTLab£©π≤Õ¨÷¬¡¶”⁄’Z(y®≥)“Ù¥Ûƒ£–Õµƒ—–∞l(f®°)£¨¥Ú‘Ï¡À∂ÀµΩ∂À’Z(y®≥)“Ù¥Ûƒ£–Õ UniTTSœµ¡–°£
°°°°∫Ü(ji®£n)ΩÈ
°°°°Æî(d®°ng)«∞£¨ª˘”⁄Îx…¢æé¥aµƒLLM-basedµƒΩ®ƒ£∑Ω∞∏ «TTS÷˜¡˜∑Ω∑®÷Æ“ª£¨∂¯“ÙÓlÎx…¢æé¥a∑Ω∞∏ï˛(hu®¨)á¿(y®¢n)÷ÿ”∞Ì냣–Õ◊ÓΩK–ßπ˚°£ƒø«∞£¨≤ø∑÷—–æø’þ墬ïåW(xu®¶)Ãÿ’˜∫Õ’Z(y®≥)¡xÃÿ’˜∑÷È_(k®°i)÷»°£¨µ´≤¢≤ª «À˘”–µƒspeech–≈œ¢∂ºþm∫œ±ª∑÷Ω‚ûÈ’Z(y®≥)¡x∫Õ¬ïåW(xu®¶)–≈œ¢£¨¿˝»Áspeech÷–µƒ–¶¬ï°¢øެﵻèä(qi®¢ng)«È∏–±Ì’˜µƒ≤ø∑÷£¨“‘º∞æþ”–ÿS∏ª±≥æ∞“ÙªÚ’þ“Ù–ßµƒ∏þŸ|(zh®¨)¡øuniversal audioîµ(sh®¥)ì˛(j®¥)°£≤ø∑÷—–æø’þ≤…”√¡ÀGRFVQ-based∂ý¥a±æ∑Ω∞∏£¨‘⁄÷…˝∆‰–‘ƒÐµƒÕ¨ïr(sh®™)£¨“≤ πµ√’Z(y®≥)“ÙÎx…¢ªØ–Ú¡–µƒ±»Ãÿ¬ º±ÀŸÃ·…˝£¨åß(d®£o)÷¬’Z(y®≥)“Ù–Ú¡–þ^(gu®∞)ÈL(zh®£ng)£¨ πµ√LLMsΩ®ƒ£’Z(y®≥)“Ù–Ú¡–ÍP(gu®°n)œµµƒÎy∂»¥Û‘ˆ£¨“Ú¥ÀµÕ¥a¬ “≤ «¥À∑Ω∞∏ÍP(gu®°n)◊¢µƒ“ªÇÄ(g®®)÷ÿ“™÷∏òÀ(bi®°o)°£±æπ§◊˜Ã·≥ˆ¡ÀDistilCodec∫ÕUniTTS£¨DistilCodec «”ñ(x®¥n)æöµ√µΩµƒÜŒ¥a±æ£¨¥a±æ¿˚”√¬ Ω”Ω¸100%«“¥a±æ¿˚”√æ˘ÑÚ£¨≤¢ª˘”⁄DistilCodec◊ˆ“ÙÓlÎx…¢ªØ£¨÷˜∏…æW(w®£ng)Ωj(lu®∞) π”√qwen2.5-7B£¨”ñ(x®¥n)æöµ√µΩUniTTSƒ£–Õ°£æþÛwπ§◊˜ÿï´I(xi®§n)»Áœ¬£∫
°°°°£®1£©≤…”√∂ý¥a±æΩÃéüƒ£–Õ£®GRVQ£©’ÙsµΩÜŒ¥a±æµƒåW(xu®¶)…˙ƒ£–Õ£®DistilCodec£©£¨þ_(d®¢)µΩΩ¸100%µƒ¥a±æ¿˚”√¬ £¨åç(sh®™)¨F(xi®§n)¡À∫Ü(ji®£n)ùç°¢∏þ–ßµƒ“ÙÓlÎx…¢æéΩ‚¥a£¨ø…ûÈ“ÙÓl¥Ûƒ£–Õ÷π©üo(w®≤)–ËΩ‚ÒÓµƒ¬ïåW(xu®¶)∫Õ’Z(y®≥)¡x“ÙÓlâ∫øs±Ì’˜°£
°°°°£®2£©±æπ§◊˜Ã·≥ˆ¡ÀUniTTS£¨∆‰ª˘”⁄DistilCodecÕÍ’˚AudioÃÿ’˜Ω®ƒ£µƒƒÐ¡¶£¨æþljÕÍ’˚’Z(y®≥)“ÙEnd2Endµƒðî»Îðî≥ˆƒÐ¡¶£¨UniTTS…˙≥…µƒ“ÙÓlæþlj∏¸◊‘»ªµƒ«È∏–±Ì¨F(xi®§n)¡¶°£
°°°°£®3£©±æπ§◊˜Ã·≥ˆ¡ÀAudio Language Model–¬µƒ”ñ(x®¥n)æö∑∂ Ω£∫DistilCodecµƒ”ñ(x®¥n)æö∑Q(ch®•ng)ûÈ“ÙÓl∏–÷™Ω®ƒ££¨∆‰÷ªå£(zhu®°n)◊¢”⁄“ÙÓlµƒÃÿ’˜Îx…¢ªØ£¨ π”√Universal audioµƒîµ(sh®¥)ì˛(j®¥)÷…˝∆‰Ùî∞Ù–‘°£UniTTSµƒ”ñ(x®¥n)æö∑Q(ch®•ng)ûÈ“ÙÓl’J(r®®n)÷™Ω®ƒ££¨∆‰∑÷ûÈpretrain°¢SFT°¢Alignment»˝ÎA∂Œ£¨‘⁄pretrainÎA∂Œ£¨ΩË÷˙DistilCodecµƒÕÍ’˚“ÙÓlÃÿ’˜Ω®ƒ£ƒÐ¡¶£¨º”»Î¡Àuniversal audioƒ£ëB(t®§i)◊‘ªÿöw»ŒÑ’(w®¥)£¨≤¢Úû(y®§n)◊C¡À∆‰”––ß–‘£ªUniTTSæþÇ‰Ω” ’»Œ“‚–Œ Ωµƒtext-audio interleaved prompt£¨À˘“‘‘⁄SFTÎA∂Œ‘îºö(x®¨)Úû(y®§n)◊C¡À≤ªÕ¨promptå¶(du®¨)”⁄TTS–‘ƒÐµƒ”∞Ì룪”…”⁄UniTTS’Z(y®≥)“Ùƒ£ëB(t®§i)“‘ÕÍ»´End2Endµƒ–Œ Ωº”»ÎµΩ¡ÀLLM÷–£¨À˘“‘ π”√÷±Ω”∆´∫√Éû(y®≠u)ªØ£¨þM(j®¨n)“ª≤Ω÷…˝’Z(y®≥)“Ù…˙≥…ƒÐ¡¶°£
°°°°UniTTS & DistilCodec UniTTSºÐòã(g®∞u)
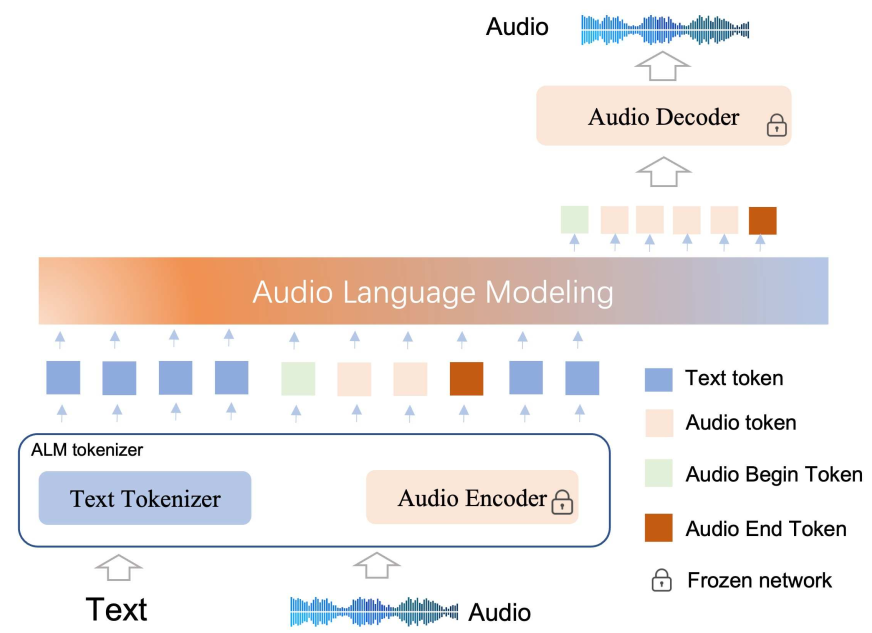
°°°°UnitTTSºÐòã(g®∞u)
°°°°UniTTSºÐòã(g®∞u)÷˜“™∞¸¿®ALM Tokenizer£¨Backbone£®Transformer£©É…ÇÄ(g®®)≤ø∑÷°£ALM Tokenizer∑÷ûÈT(m®¶n)ext Tokenizer∫ÕAudio Encoder£¨Text TokenizerÕÍ≥…Œƒ±æµƒ∑÷‘~£¨Audio EncoderÕÍ≥…“ÙÓlµƒ∑÷‘~∫Õ÷ÿòã(g®∞u)°£Backboneª˘”⁄TransformerºÐòã(g®∞u)åç(sh®™)¨F(xi®§n)É…∑Nƒ£ëB(t®§i)tokenµƒΩªÃÊ◊‘ªÿöw°£
°°°°ƒ£–ÕºÐòã(g®∞u) π”√“ªÇÄ(g®®)ÜŒ¥a±ætokenizer∫Õ“ªÇÄ(g®®)decoder-onlyƒ£–Õ°£ûÈ¡À墓ÙÓlÎx…¢ªØûÈtoken£¨≤¢”√¥Ûƒ£–ÕΩ®ƒ£token÷ÆÈgµƒÍP(gu®°n)œµ£¨ ◊œ»”ñ(x®¥n)æö¡À“ªÇÄ(g®®)¥a±æ¿˚”√¬ Ω”Ω¸100%ÜŒ¥a±æcodec£®DistilCodec£©£¨÷˜∏…æW(w®£ng)Ωj(lu®∞) π”√qwen2.5-7Bƒ£–Õ£¨‘⁄ƒ£–Õ‘≠ÅÌ(l®¢i)µƒ‘~±Ì∫Û–¬‘ˆ32K“ÙÓltoken£¨“Ú¥ÀîU(ku®∞)≥‰∫Ûµƒ‘~±Ìπ≤”ã(j®¨)180k°£ƒ£–Õ”ñ(x®¥n)æö÷˜“™∑÷≥…É…ÇÄ(g®®)≤ø∑÷£¨“ÙÓl∏–÷™Ω®ƒ£“‘º∞“ÙÓl’J(r®®n)÷™Ω®ƒ££¨∆‰÷–“ÙÓlƒ£ëB(t®§i)∏–÷™Ω®ƒ£þ^(gu®∞)≥Ã≤ªþM(j®¨n)––’Z(y®≥)¡xå¶(du®¨)˝R£¨å£(zhu®°n)◊¢”⁄“ÙÓlÃÿ’˜µƒÎx…¢ªØ“‘º∞“ÙÓl÷ÿΩ®£ª‘⁄“ÙÓlƒ£ëB(t®§i)’J(r®®n)÷™Ω®ƒ£þ^(gu®∞)≥Ã÷–£¨‘⁄“—”–’Z(y®≥)—‘ƒ£–Õµƒª˘µA(ch®≥)…œ£¨å¢“ÙÓlƒ£ëB(t®§i)∫ÕŒƒ±æƒ£ëB(t®§i)þM(j®¨n)––»⁄∫œ£¨åç(sh®™)¨F(xi®§n)“ÙÓlµƒ’J(r®®n)÷™Ω®ƒ£°£
°°°°DistilCodecΩY(ji®¶)òã(g®∞u)
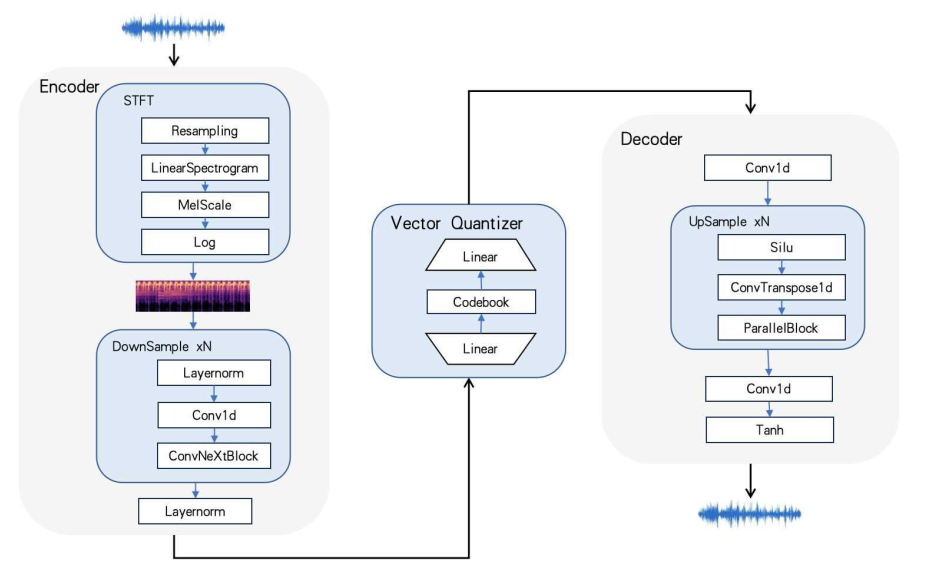
°°°°DistilCodecæW(w®£ng)Ωj(lu®∞)ΩY(ji®¶)òã(g®∞u)
°°°°DistilCodecæW(w®£ng)Ωj(lu®∞)ΩY(ji®¶)òã(g®∞u)»Á…œ£¨Õ®þ^(gu®∞)∏µ¡¢»~◊ÉìQ墓ÙÓlÞD(zhu®£n)ûÈÓl◊V£¨≤¢”…∂—ØBµƒöà≤ÓæÌ∑eå”åç(sh®™)¨F(xi®§n)Ãÿ’˜â∫øs£¨‘⁄¡øªØ∆˜£®Quantizer£©÷–Õ®þ^(gu®∞)æÄ–‘å”å¢â∫øsÃÿ’˜Õ∂”∞µΩ¥a±æœÚ¡øýè”Ú£¨∆‰å¶(du®¨)ë™(y®©ng)ýè”Ú÷––ƒµƒÀ˜“˝◊˜ûÈ‘ì“ÙÓl∆¨∂ŒµƒÎx…¢±Ì’˜°£‘⁄∑¥œÚ÷ÿòã(g®∞u)þ^(gu®∞)≥Ã÷–£¨Õ®þ^(gu®∞)GANæW(w®£ng)Ωj(lu®∞)÷ÿòã(g®∞u)ûÈå¶(du®¨)ë™(y®©ng)“ÙÓl∆¨∂Œ°£
°°°°DistilCodec”ñ(x®¥n)æö
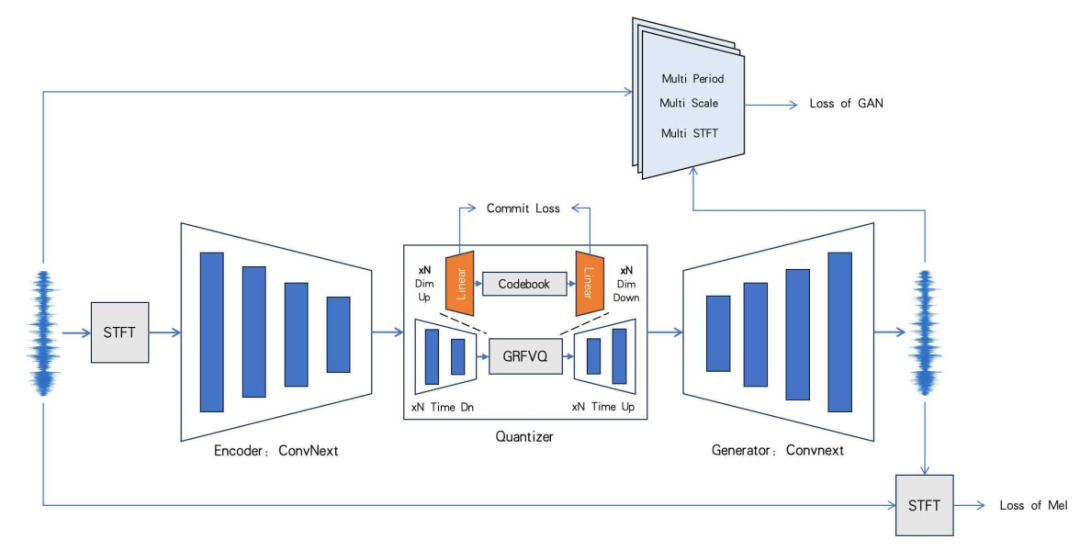
°°°°DistilCodec”ñ(x®¥n)æöþ^(gu®∞)≥Ã
°°°°…œàD’π æ¡ÀDistilCodecµƒ”ñ(x®¥n)æöþ^(gu®∞)≥ð£ûÈ¡Àåç(sh®™)¨F(xi®§n)ÜŒ“ª≥¨¥ÛCodebookµƒCodec”ñ(x®¥n)æö£¨ ◊œ»Õ®þ^(gu®∞) π”√GVQ°¢RVQº∞FVQΩY(ji®¶)∫œµƒ∑Ω Ω£¨”ñ(x®¥n)æö¡À“ªÇÄ(g®®)ìÌ”–32ÇÄ(g®®)CodebookµƒTeacher Codec£¨»ª∫Û π”√Teacher CodecµƒAudio-Encoder∫ÕAudio-DecoderµƒÖ¢îµ(sh®¥)≥ı ºªØ“ªÇÄ(g®®)Student Codec£¨¥ÀCodec «“ªÇÄ(g®®)Residual∫ÕGroupæ˘ûÈ1µƒÜŒ“ª¥a±æ£¨µ´ «∆‰Codebookµƒ¥a±æ¥Û–° «Teacher CodecµƒøÇ∫Õ°£
°°°°UniTTSÓA(y®¥)”ñ(x®¥n)æö£®Pretrain£©
°°°°œýð^”⁄Œƒ±æΩ®ƒ££¨“ÙÓlΩ®ƒ£æþ”–∏¸¥Ûµƒ±Ì æø’Èg°£“Ú¥À£¨¥Û“é(gu®©)ƒ£∏þŸ|(zh®¨)¡øŒƒ±æ-“ÙÓl≈‰å¶(du®¨)îµ(sh®¥)ì˛(j®¥) «åç(sh®™)¨F(xi®§n)Õ®”√“ÙÓl◊‘ªÿöwµƒ«∞÷°£UniTTS‘O(sh®®)”ã(j®¨)¡À“ªÃ◊∂ýÎA∂ŒµƒÓA(y®¥)”ñ(x®¥n)æö∑Ω∑®°£‘⁄µ⁄“ªÎA∂Œ£∫‘⁄ÓA(y®¥)”ñ(x®¥n)æöµƒŒƒ±æƒ£–Õª˘µA(ch®≥)…œ£¨ πƒ£–Õ‘⁄Œƒ±æîµ(sh®¥)ì˛(j®¥)°¢Õ®”√“ÙÓlîµ(sh®¥)ì˛(j®¥)∫Õ“ª∂®îµ(sh®¥)¡øµƒŒƒ±æ-“ÙÓl≈‰å¶(du®¨)îµ(sh®¥)ì˛(j®¥)…œþM(j®¨n)“ª≤Ω”ñ(x®¥n)æö£¨ πƒ£–ÕåW(xu®¶)¡ï(x®™)“ÙÓlΩ®ƒ£°£»ª∂¯£¨å¢“ÙÓl”ñ(x®¥n)æöîµ(sh®¥)ì˛(j®¥)÷±Ω”“˝»ÎÓA(y®¥)”ñ(x®¥n)æöµƒŒƒ±æƒ£–Õ£¨ï˛(hu®¨)åß(d®£o)÷¬ƒ£ëB(t®§i)∏Ç(j®¨ng)Ýé(zh®•ng)£¨ƒ£–ÕµƒŒƒ±æ…˙≥…ƒÐ¡¶ÕÀªØ°£ûÈ¥À£¨‘⁄µ⁄∂˛ÎA∂Œ£∫ΩY(ji®¶)∫œª˘”⁄Œƒ±æµƒ÷∏¡Óîµ(sh®¥)ì˛(j®¥)ºØ£¨“‘º∞¨F(xi®§n)”–µƒÕ®”√“ÙÓl∫ÕŒƒ±æ-“ÙÓl≈‰å¶(du®¨)îµ(sh®¥)ì˛(j®¥)ºØ£¨þM(j®¨n)“ª≤Ω‘ˆèä(qi®¢ng)ƒ£–ÕµƒŒƒ±æ…˙≥…ƒÐ¡¶°£¥ÀÕ‚£¨ûÈ¡Àþmë™(y®©ng)∏¸ÈL(zh®£ng)µƒ…œœ¬Œƒ–Ú¡–£¨“ÙÓl”ñ(x®¥n)æö“™«Û境£–Õµƒ…œœ¬Œƒ¥∞ø⁄¥Û–°£¨èƒ8,192îU(ku®∞)’πµΩ16,384£¨“‘þmë™(y®©ng)æþ”–ÈL(zh®£ng)–Ú¡–Ãÿ–‘µƒ“ÙÓlƒ£ëB(t®§i)îµ(sh®¥)ì˛(j®¥)°£
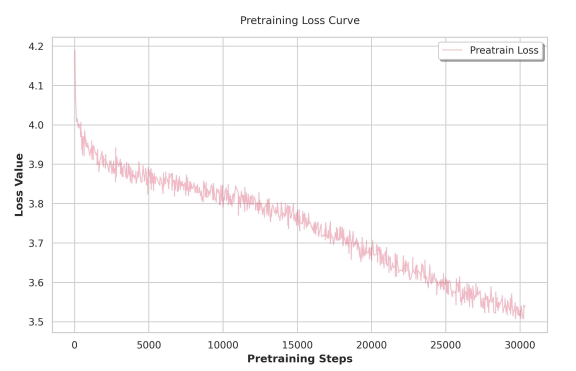
°°°°ÓA(y®¥)”ñ(x®¥n)æöìp ß«˙æÄ
°°°°UniTTS÷∏¡ÓŒ¢’{(di®§o)£®SFT£©
°°°°‘⁄±O(ji®°n)∂ΩŒ¢’{(di®§o)þ^(gu®∞)≥Ã÷–£¨îµ(sh®¥)ì˛(j®¥)Ÿ|(zh®¨)¡øå¢Ô@÷¯”∞Ì냣–Õ◊ÓΩKµƒƒÐ¡¶°£¨F(xi®§n)”–È_(k®°i)‘¥Œƒ±æ-“ÙÓl≈‰å¶(du®¨)îµ(sh®¥)ì˛(j®¥)ºØ”–“ª∂®»±œð£¨¿˝»Á£∫1£©Ö¢øºŒƒ±æÕ®≥£ÅÌ(l®¢i)◊‘ASRòÀ(bi®°o)◊¢£¨πÔ–µÿ∞¸∫¨‘άï 2£©¥Û¡øò”±æ»°◊‘”⁄”–¬ïï¯(sh®±)ºÆ°¢≤©øÕµ»ÅÌ(l®¢i)‘¥£¨Õ˘Õ˘∞¸∫¨ð^ÈL(zh®£ng)µƒ≥¡ƒ¨∆¨∂Œ°£þ@ï˛(hu®¨)TTSƒ£–Õµƒ…˙≥…–ßπ˚°£ûÈ¥À£¨UniTTS ‘O(sh®®)”ã(j®¨)¡À“ª∑Nåç(sh®™)”√µƒèÕ(f®¥)∫œŸ|(zh®¨)¡ø‘u(p®™ng)∑÷∑Ω∑®þ^(gu®∞)ûVò”±æ£∫
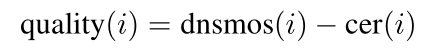
°°°°∆‰÷–£¨dnsmos”––ßµÿþ^(gu®∞)ûV“ÙÓl¬ïåW(xu®¶)Ÿ|(zh®¨)¡ø£¨CER±Ì æûÈ÷ÿòÀ(bi®°o)◊¢µƒÂe(cu®∞)◊÷¬ £¨ø…þM(j®¨n)“ª≤Ωþ^(gu®∞)ûVòÀ(bi®°o)◊¢Âe(cu®∞)’`°£ª˘”⁄Qualityµƒ÷ÿ≈≈∫ÕÈì÷µ∫Yþx£¨ø…”––ßÉû(y®≠u)ªØ”ñ(x®¥n)æöò”±æµƒŸ|(zh®¨)¡ø°£
°°°°UniTTS∆´∫√å¶(du®¨)˝R£®Alignment£©
°°°°SFTø… πƒ£–Õ”––ßåW(xu®¶)¡ï(x®™)Ãÿ∂®’Z(y®≥)“Ù»ŒÑ’(w®¥)µƒƒ£ Ω£¨µ´“ª∂®≥Ã∂»…œï˛(hu®¨)Æa(ch®£n)…˙Ì笅—”ÈL(zh®£ng)°¢÷ÿèÕ(f®¥)µƒÜñ(w®®n)Ó}£®Óê(l®®i)À∆Œƒ±æ”ÚµƒèÕ(f®¥)◊x¨F(xi®§n)œÛ£©°£ûÈ¥À£¨UniTTS≤…”√÷±Ω”∆´∫√Éû(y®≠u)ªØ£®DPO£©þM(j®¨n)“ª≤ΩÉû(y®≠u)ªØƒ£–Õ–ßπ˚£¨µ´å¶(du®¨)”⁄ÈL(zh®£ng)–Ú¡–“ÙÓlΩ®ƒ£∂¯—‘£¨DPO»ð“◊≥ˆ¨F(xi®§n)ƒ£ Ω±¿ù¢°£“Ú¥À£¨UniTTS“˝»ÎæÄ–‘∆´∫√Éû(y®≠u)ªØ∑Ω∑®£®LPO£©◊˜ûÈDPOµƒÃÊ¥˙∑Ω∞∏£∫
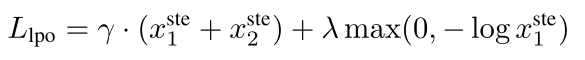
°°°°‘⁄LPOìp ß÷–£¨x1°¢x2∑÷ÑeûÈ’˝°¢ÿì(f®¥)ò”±æ≤…ò”≤þ¬‘∆´∫√£¨Õ®þ^(gu®∞)“÷÷∆’˝ÿì(f®¥)ò”±æµƒ÷±Õ®≤þ¬‘π¿”ã(j®¨)£¨≤¢–°∑˘¥ŸþM(j®¨n)’˝ò”±æ≤þ¬‘“‘–Þ’˝ƒ£–Õ≤þ¬‘Ãð∂»∑ΩœÚ£¨∑Ä(w®ßn)∂®ÈL(zh®£ng)–Ú¡–∆´∫√Éû(y®≠u)ªØ”ñ(x®¥n)æö°£
°°°°åç(sh®™)Úû(y®§n)ΩY(ji®¶)π˚
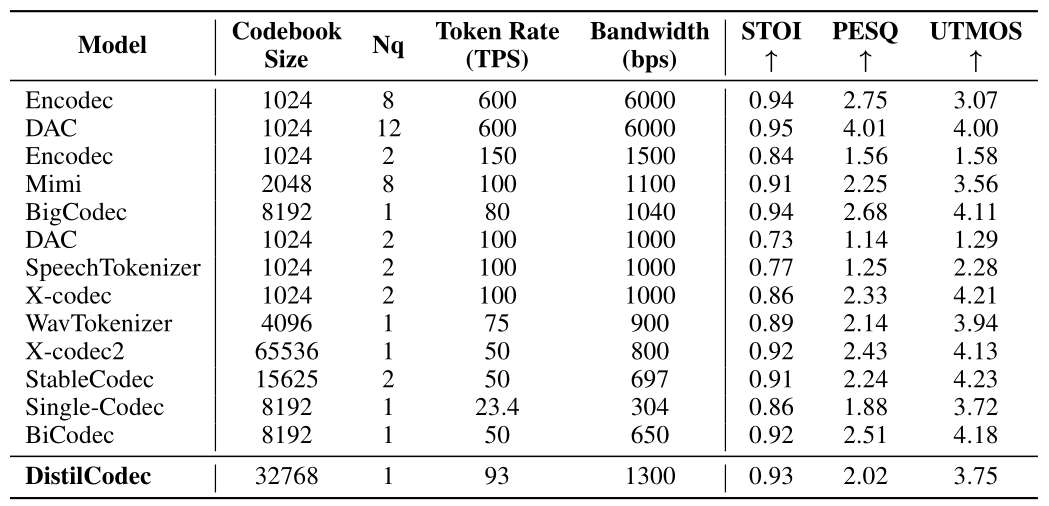
°°°°‘⁄åç(sh®™)Úû(y®§n)≤ø∑÷£¨≤…”√LibriSpeech-Cleanîµ(sh®¥)ì˛(j®¥)ºØ∫Õ◊‘Ω®Universal Audioîµ(sh®¥)ì˛(j®¥)ºØÅÌ(l®¢i)‘u(p®™ng)π¿DistilCodecµƒ¿ßªÛ∂»£®PPL£©∫Õ¥a±æ¿˚”√¬ £®Usage£©£¨œýë™(y®©ng)µƒåç(sh®™)Úû(y®§n)ΩY(ji®¶)π˚»Áœ¬°£‘⁄’Z(y®≥)“Ù∫ÕÕ®”√“ÙÓlîµ(sh®¥)ì˛(j®¥)ºØ…œ£¨DistilCodecåç(sh®™)¨F(xi®§n)¡ÀΩ¸∫ı◊Óº—µƒ¥a±æ¿˚”√¬ £®Ω”Ω¸100%£©°£åç(sh®™)Úû(y®§n)÷–£¨Œ“ÇÉþÄ π”√LibriSpeech-Clean-Test Benchmarkå¶(du®¨)DistilCodecµƒ’Z(y®≥)“Ù÷ÿΩ®ƒÐ¡¶þM(j®¨n)––¡À»´√ʵƒå¶(du®¨)±»∑÷Œˆ°£
°°°°èƒœ¬±Ì÷–ø…“‘ø¥µΩ£¨DistilCodecµƒ¥a±æ¿˚”√¬ Ω”Ω¸100%£¨Õ¨ïr(sh®™)¥a±æ¿˚”√æ˘∫‚£¨“Ú¥ÀDistilCodecå¶(du®¨)”⁄’Z(y®≥)“ÙµƒÎx…¢ªØæþlj“ª∂®µƒ–‘ƒÐ°£

°°°°¥a±æ¬ ”√¬ ∫տߪÛ∂»å¶(du®¨)±»
°°°°‘⁄LibriSpeechµƒClean∫ÕOtherîµ(sh®¥)ì˛(j®¥)ºØ£¨þM(j®¨n)––‘u(p®™ng)π¿£¨DistilCodec‘⁄1KBPS◊Û”“µƒcodecœ¬£¨STOI÷∏òÀ(bi®°o)þ_(d®¢)µΩ¡ÀSOTA£¨‘îºö(x®¨)÷∏òÀ(bi®°o)»Áœ¬±ÌÀ˘ æ°£
°°°°≤ªÕ¨Codecƒ£–ÕæC∫œå¶(du®¨)±»
°°°°ûÈ¡ÀþM(j®¨n)––á¿(y®¢n)∏Òµƒ‘u(p®™ng)π¿£¨Œ“ÇÉ“≤å¢UniTTS≈c¨F(xi®§n)”–∑Ω∑®þM(j®¨n)––å¶(du®¨)±»£¨÷˜“™∞¸¿®£∫CosyVoice2°¢Spark-TTS°¢LLaSA°¢F5-TTS Fish-Speech°¢IndexTTS°£ΩY(ji®¶)π˚±Ì√˜£¨≈cUniTTS-SFTœý±»£¨UniTTS-LPO‘⁄«È∏–±Ì¨F(xi®§n)¡¶°¢±£’Ê∂»∫Õ◊‘»ª∂»∑Ω√Ê»°µ√¡À»´√ʵƒþM(j®¨n)≤Ω£¨Úû(y®§n)◊C¡ÀLPO”ñ(x®¥n)æö∑Ω∑®µƒ”––ß–‘°£UniTTS-LPOµƒ–‘ƒÐ÷…˝£¨÷˜“™‘¥”⁄”…’ÙsΩ‚¥aÚå(q®±)Ñ”(d®∞ng)µƒÌ笅-“Ù…´-«È∏–Ãÿ’˜µƒ’˚ÛwΩ®ƒ££¨“‘º∞∂ýò”ªØµƒüo(w®≤)±O(ji®°n)∂Ω”ñ(x®¥n)æö°£

°°°°ΩY(ji®¶)’Z(y®≥)
°°°°Õ®þ^(gu®∞)∏þ–ßµƒÎx…¢æéΩ‚¥aºº–g(sh®¥)£¨DistilCodecåç(sh®™)¨F(xi®§n)‘⁄ÜŒ¥a±æàˆ(ch®£ng)æ∞œ¬¿˚”√¬ Ω”Ω¸100%£¨≤¢«“¥a±æ¿˚”√æ˘ÑÚ£¨”––ßµÿÕÿ’π¡À“ÙÓl¥Ûƒ£–Õ‘⁄∂ý∑N“ÙÓl»ŒÑ’(w®¥)…œµƒë™(y®©ng)”√ù졶£¨ûÈ≤ªÕ¨“ÙÓlàˆ(ch®£ng)æ∞œ¬µƒþmë™(y®©ng)–‘µÏ∂®¡Àª˘µA(ch®≥)°£UniTTS≤…”√»˝ÎA∂Œ”ñ(x®¥n)æö≤þ¬‘£¨åç(sh®™)¨F(xi®§n)∑Ä(w®ßn)∂®µƒ¥Ûƒ£–ÕøÁƒ£ëB(t®§i)”ñ(x®¥n)æö°£‘⁄»ÀôC(j®©)Ωªª•µƒ±≥æ∞œ¬£¨UniTTS≤ªÉH÷…˝¡À’Z(y®≥)“ÙΩªª•µƒ◊‘»ª∂»∫Õ¡˜ï≥–‘£¨ûÈ”√ëÙéßÅÌ(l®¢i)¡À∏¸∏ª”–«È∏–∫ÕÇÄ(g®®)–‘µƒΩªª•ÛwÚû(y®§n)°£
ÍP(gu®°n)◊¢Õ¨ª®Ìòÿî(c®¢i)Ωõ(j®©ng)£®ths518£©£¨´@»°∏¸∂ýôC(j®©)ï˛(hu®¨)
0»À
| ¥˙¥a|π…∆±√˚∑Q(ch®•ng) | ◊Ó–¬ | ùqµ¯∑˘ |
|---|



